Fungsi dan perbedaan SPSS dan Ms. Excel pada aplikasi Komputer
SPSS
 |
| SPSS |
SPSS adalah program aplikasi bisnis yang berguna untuk menganalisa data statistik. Versi terbaru program ini adalah
SPSS 20, yang dirilis pada tanggal 16 Agustus 2011. Software SPSS dibuat dan dikembangkan oleh
SPSS Inc. yang kemudian diakuisisi oleh IBM Corporation.
Perangkat lunak komputer ini memiliki kelebihan pada kemudahan
penggunaannya dalam mengolah dan menganalisis data statistik. Fitur yang
ditawarkan antara lain IBM SPSS Data Collection untuk pengumpulan data,
IBM SPSS Statistics untuk menganalisis data, IBM SPSS Modeler untuk
memprediksi tren, dan IBM Analytical Decision Management untuk
pengambilan keputusannya.
Program
SPSS banyak diaplikasikan dan digunakan oleh kalangan pengguna komputer di bidang
bisnis, perkantoran, pendidikan, dan penelitian. SPSS merupakan
software komersial
dengan harga lisensi $5,120 USD. SPSS dapat dijalankan di sistem
operasi Windows XP, Windows Vista, Windows 7, Mac OS, dan Linux. Untuk
menginstall versi terbaru program ini, komputer Windows Anda harus
memiliki spesifikasi minimal menggunakan prosesor Intel atau AMD dengan
kecepatan 1 GHz, memori (RAM) 1 GB, resolusi monitor 1024x768 piksel,
dan harddisk dengan kapasitas kosong minimal 800 MB.
SPSS dan MS Excel pada Aplikasi Komputer
(Postingan ini ditulis untuk memenuhi tugas mata kuliah Aplikasi Komputer)
Rangkuman Materi Kuliah Aplikasi Komputer Semester V Kelas Anvulen FKM Universitas Widia Gama Mahakam
Mata kuliah Aplikasi Komputer merupakan
lanjutan dari Mata Kuliah Pengantar Komputer di Semester III. Sebagian
kuliah merupakan praktik komputer yang berkaitan dengan program
Microsoft Excel, serta program SPSS. Di sini diajarkan bagaimana
menuliskan perintah ke komputer, bagaimana mengkonversi rumus, dan
bagaimana menganalisa hasil.
Penggunaan rumus dasar dalam Excel
Ms Excel berfungsi untuk
hitung-menghitung. Kita bisa menghitung dengan menggunakan rumus atau
fungsi-fungsi yang telah disediakan Microsoft. Kita bisa menggunakan
operator matematika untuk membuat rumus di Excel.
- Cara menuliskan rumus dalam komputer
- Pangkat : ^ contoh: 5³ –> 5^3
- Akar : sqrt (khusus untuk diakarkan 2). Contoh: sqrt 25 = √25
- Perkalian : *
- Pembagian : /
- Plus/minus : +/-
– Tingkat level perhitungan (TLP) yang harus diperhatikan
- Pangkat dan akar (√)
- Kali dan bagi (* dan /)
- Plus dan minus +/-
- Tanda kurung (lebih utama)
– Contoh perhitungan : 5-5^2+6^2+2×2+5-6-9=10
– Memasukkan rumus
- Pilih cell yang dijadikan tempat hasil perhitungan
- Awali rumus dengn lambang ‘sama dengan’ (=)
- Masukkan rumus yang akan digunakan
- Tekan enter pada keyboard
- Belajar Fungsi IF pada Ms Excel
Rumus IF digunakan untuk mengetahui suatu
nilai/karakter dalam sebuah cell terpenuhi atau tidak terpenuhi, dari
hasil tersebut kita bisa menentukan nilai/karakter apa yang akan
ditampilkan si dalam cell pada Ms Excel.
Bentuk penulisan rumus IF –> IF(logical_test,[value_if_true],[value_if_false])
Keterangan:
logical_test : kriteria/nilai yang akan dipakai
value_if_true : nilai yang akan ditampilkan jika kriteria/nilai yang diuji terpenuhi
value _if_false : nilai yang akan ditampilkan jika kriteria/nilai yang diuji tidak terpenuhi
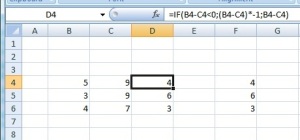
Perhatikan
pada kolom D. Bila pengurangan kolom B terhadap kolom C berjumlah
kurang dari nol, maka hasil pengurangan itu dikalikan dengan -1. Bila
tidak kurang dari nol, maka akan tetap berisi jumlah pengurangan kolom B
terhadap kolom C.
- Fungsi logika IF majemuk
Fungsi ini digunakan untuk menyeleksi
beberapa kondisi yang menghasilkan nulai TRUE/FALSE bentuk umum :
=IF(Kondisi 1;Pernyataan 1;IF(Kondisi 2;Pernyataan 2; Pernyataan 3))
- Fungsi VLOOKUP
Fungsi ini digunakan untuk membaca suatu
tabel. Bila tabel disusun secara vertikal, digunakan fungsi VLOOKUP.
Penulisan fungsi VLOOKUP memiliki bentuk sebagai berikut:
=VLOOKUP(Lookup_value, Table_array, Col_index_num)
Catatan; Nomor indeks kolom
(Col_index_num) merupakan angka untuk menyatakan posisi suatu kolom
dalam tabel. Sedangkan nomor indeks baris (Row_index_num) merupakan
angka untuk menyatakan baris dalam tabel tersebut.
***
Penggunaan SPSS (Statistical Package for the Social Science)
SPSS merupakan program aplikasi untuk
melakukan perhitungan statistik dengan menggunakan komputer. Yang perlu
dikakuan adalah mendesain variabel yang akan dianalisis, memasukkan
data, dan melakukan perhitungan dengan menggunakan tahapan yang ada pada
menu yang tersedia. Setelah itu, hasil perhitungan dianalisis.
Contoh penggunaan program SPSS
Perhitungan Chi- Square:
Saat musim mangga, dilakukan penelitian pada 48 pasien di Puskesmas A. Data lengkap pada tabel di bawah ini.

Apakah ada hubungan antara konsumsi mangga dengan kejadian diare di wilayah XX, Puskesmas A? Chi tabel : 3, 841
Langkah-langkah yang dilakukan:
H0 : Tidak ada hubungan antara kejadian diare dengan konsumsi mangga
Ha : Ada hubungan antara kejadian diare dengan konsumsi mangga
1. Buka program SPSS
 Tampilan SPSS
Tampilan SPSS
2. Klik variable view yang ada pada
bagian kiri bawah. Lalu isi variabel yang sesuai. Tuliskan nama variabel
‘sakit’ dan ‘perilaku’, tipe data (numerik), label. Pada values, isikan
label values variabel sakit dengan angka 1=sakit dan 2=tidak sakit.
Lalu label values variabel perilaku 1 = makan mangga dan 2 = tidak makan
mangga.
 Tampilan variable view
Tampilan variable view
3. Klik ‘Data View’. Pada kolom ‘sakit’, masukkan angka 1 (sakit)
dari baris 1-30, dan angka 2 (tidak sakit) dari baris 31-48. Kemudian
pada kolom ‘perilaku’, tuliskan angka 1 dari baris 1-21, angka 2 pada
baris 22-30. Lalu angka 1 lagi pada baris 31-38, dan angka 2 pada baris
39-48.
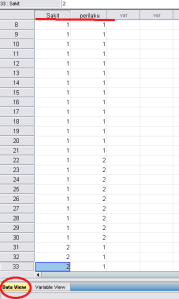 Tampilan Data View
Tampilan Data View
4. Klik ‘analyze’ pada deretan menu. Pilih ‘Descriptive statistic’, kemudian klik ‘crosstab’.
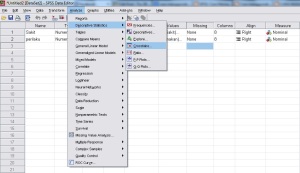 Menganalisa data
Menganalisa data
Akan muncul sebuah jendela Crosstab. Klik
variabel ‘perilaku’ dan masukkan ke ‘row’. Lalu variabel ‘sakit’ pada
‘coloumn’. Pada bagian ‘Statistics’ beri tanda conteng pada
‘chi-square’. Lalu klik OK.
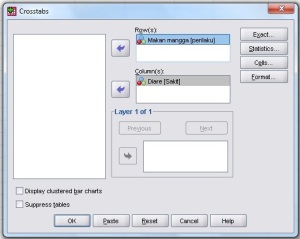 Crosstabulasi
Crosstabulasi
5. Akan muncul output seperti di bawah ini.
 Output SPSS
Output SPSS
Hasil perhitungannya terlihat seperti pada tabel di bawah ini.
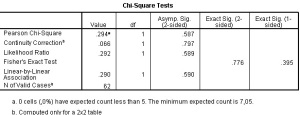 Hasil perhitungan
Hasil perhitungan
Jadi nilai yang dilihat untuk tabel 2×2
adalah pada pada ‘b’, nilainya 0, 066. Lebih kecil dibanding Chi tabel.
Maka Ho diterima. Yang artinya bahwa tidak ada hubungan antara kejadian
diare dengan konsumsi mangga.
Contoh di atas hanya segelintir dari
pemanfaatan program SPSS untuk mempermudah perhitungan statistik. Ada
banyak pilihan analisa yang bisa digunakan sesuai penelitian yang
dilakukan.
Dasar-Dasar SPSS
Bagi kebanyakan orang, proses pengolahan data statistik masih
dipandang sebagai proses perhitungan matematis yang sulit dan akan
memakan waktu yang cukup lama. Namun kini, dengan perkembangan di bidang
Information Technology (IT), proses pengolahan data tersebut menjadi sesuatu yang sangat mudah dan cepat
.
Software
pengolah data bukanlah sesuatu yang sulit dicari, dari yang hampir
selalu ada di setiap komputer (misalnya Microsoft Excel) sampai yang
lebih canggih seperti SPSS atau MINITAB.
Kita dapat menggunakan software seperti Excel untuk menghitung rata-rata dan membuat analisis sederhana seperti linear regression atau histogram. Umumnya, analisis Excel seperti ini sudah cukup, namun dalam banyak hal kita sering memerlukan analisis yang lebih lengkap; software
seperti SPSS, MINITAB, STATISTICA dapat membantu kita menganalisis data
secara lebih lengkap. Excel sendiri dapat menyamai kemampuan ketiga software tersebut dengan cara melengkapinya dengan beberapa adds-on tertentu yang dapat kita download dari internet. Gambar 1 berikut memperlihatkan tampilan beberapa software statistik yang disebutkan tadi.
Gambar 1. Contoh-contoh Software Pengolah Data Statistik
Sotware-software statistik tidak terbatas empat software yang ditunjukkan di atas. Namun, jika disebutkan software
statistik maka yang pertama kali terbayang di benak banyak orang adalah
SPSS. Kepopuleran SPSS inilah yang menarik minat saya untuk membuat
tulisan ini. Pada dasarnya, saya sendiri kurang familiar dan kurang suka dengan SPSS, tetapi bagaimanapun SPSS sering dijadikan dasar pengenalan software statistik di berbagai perguruan tinggi.
SPSS dikembangkan sejak 1968 oleh
Norman H. Nie, C. Hadlai (Tex) Hull, dan Dale H. Bent di
Stanford University. Pada awalnya,
software statistik ini diperuntukan untuk menyelesaikan analisis-analisis statistik dalam penelitian sosial (
social science) sehingga dinamai SPSS yang merupakan singkatan dari
Statistical Package for the Social Science. Seiring dengan fungsinya yang kian berkembang, SPSS mengubah kepanjangannya menjadi
Statistical Product and Service Solution.
Saat ini, saya menggunakan SPSS 14.0 for Evaluation Version yang
dirilis 5 september 2005. Fungsi-fungsinya tidak beda jauh dengan SPSS
11 yang biasa saya pakai di laboratorium kampus.
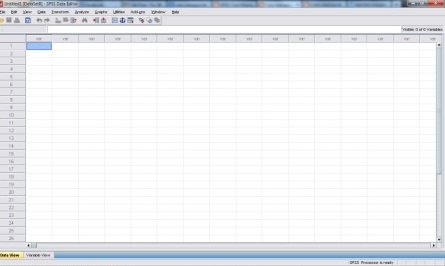
Pada versi 14, ketika anda membuka SPSS akan muncul dua jendela program yang satu bertuliskan SPSS Data Editor dan yang satunya lagi bertuliskan SPSS Viewer.
Gambar 2. SPSS Data Editor & SPSS Viewer
SPSS Data Editor merupakan tempat untuk entry data dan melakukan perintah analisis, sedangkan SPSS Viewer akan menampilkan hasil dari analisis SPSS. Pembahasan paling penting untuk pengenalan SPSS ini adalah pada jendela SPSS Data Editor.
SPSS Data Editor
SPSS Data Editor terdiri dari dua
tab sheet, yaitu:
Data View dan
Variable View.
a. Data View
Data View adalah
tab sheet yang menampilkan nilai data yang sebenarnya atau label nilai yang didefinisikan. Pada
tab sheet inilah, anda mengentri data ke SPSS (lihat Gambar 3). Diatasnya terdapat menu-menu seperti
File,
Edit,
View,
Windows, dan
Help seperti halnya menu-menu umum pada aplikasi under Windows lainnya. Menu-menu utama SPSS adalah:
- Data. Menu ini menampilkan submenu untuk melakukan perubahan-perubahan data, seperti mengurutkan data, memisahkan isi file dengan kriteria tertentu, menggabungkan data, etc.
- Transform. Menu untuk transformasi data, seperti menghitung variabel data, mengubah data, merangking data, etc.
- Analyze. Menu yang menjadi pusat pengolahan data, seperti mengolah statistik deskriptif, regresi, korelasi, etc.
- Graphs. Menu untuk menampilkan data dan hasil pengolahan data dalam bentuk grafik dan chart, seperti bar charts, histogram, scatter diagram, etc.
- Utilities. Menu
pelengkap dalam pengoperasian SPSS, seperti menampilkan informasi
variabel, mendefinisikan dan menampilkan variabel data, etc.
b. Variable View
Variable View adalah
tab sheet yang menampilkan kamus
metadata di mana setiap baris mewakili sebuah variabel dan memperlihatkan nama variabel, jenis data (misal:
numeric, string, date), lebar cetak, dan berbagai karakteristik lain.
Menu yang tersedia dalam Variabel View diantaranya:
- Name. Kolom ini untuk memberikan informasi tentang nama variabel data. Nama variabel yang kita tuliskan di sini akan muncul pada Data View. Beberapa aturan penamaan variabel:
- Nama variabel maksimal 8 karakter.
- Nama diawali dengan huruf (tidak bisa dimulai dengan angka), sisanya
dapat berisi huruf, angka, titik, atau simbol @, #, _, atau $. Kosong
dan karakter khusus lain (misal: ! , ? , ‘ , dan *) tidak dapat
digunakan.
- Nama tidak bisa berakhir dengan titik dan tidak harus diakhiri dengan garis bawah “_”.
- nama variabel harus unik; duplikasi tidak diperbolehkan.
- Nama-nama variabel tidak case sensitif, “Nama”, “nama”, dan “naMa” semua dianggap sama.
 Type. Kolom ini untuk memberikan jenis variabel data yang digunakan, apakah Numeric, String (data berupa karakter, misal “Nama”), Date, etc. Klik ikon
Type. Kolom ini untuk memberikan jenis variabel data yang digunakan, apakah Numeric, String (data berupa karakter, misal “Nama”), Date, etc. Klik ikon  dalam kolom Type maka akan muncul dialog box Variable Type. Pada dialog box ini, kita dapat mengubah jenis data dan juga lebar kolom (Width) dan jumlah angka desimal (Decimal Places). Secara default, SPSS memberikan jenis data numeric dengan lebar 8 digit dan 2 angka desimal di belakang koma.
dalam kolom Type maka akan muncul dialog box Variable Type. Pada dialog box ini, kita dapat mengubah jenis data dan juga lebar kolom (Width) dan jumlah angka desimal (Decimal Places). Secara default, SPSS memberikan jenis data numeric dengan lebar 8 digit dan 2 angka desimal di belakang koma.
- Label. Kolom ini menunjukkan tambahan informasi dengan memberi label pada variabel data yang kita inginkan. Misalnya:
variabel: ”barang” kita beri label: ”nama barang”
variabel: ”X” kita beri label ”Permintaan”
variabel ”Y” kita beri label ”Ramalan Permintan”
Pemberian label dapat membantu dalam interpretasi hasil analisis (output) karena definisi output lebih jelas.
- Value. Kolom ini untuk memberikan label string yang diterapkan untuk nilai numeric tertentu, biasanya untuk data yang bersifat ordinal dan interval, misal angka 1 untuk laki-laki dan angka 2 untuk perempuan. Klik ikon pada kolom Values maka akan muncul dialog box Value Labels. Misalnya untuk variabel ”gender” kita akan mendefinisikan ”jenis kelamin” dengan memberi label: Isi [Value] dengan angka 1 dan [Label] dengan “Laki-laki” lalu klik [Add], kemudian ulangi langkah-langkah tersebut untuk jenis kelamin “Perempuan“—lihat Gambar 6. Nantinya pada variabel gender, kita tidak perlu menuliskan laki-laki dan perempuan melainkan cukup mengisi 1 untuk laki-laki dan 2 untuk perempuan.
- Missing. Kolom ini menunjukkan nilai yang hilang (missing value)
dalam data (jika ada). Responden dapat menolak untuk menjawab
pertanyaan tertentu, mungkin tidak tahu jawabannya, atau mungkin
menjawab dalam bentuk lain. Jika anda tidak mengidentifikasi data ini,
analisis anda mungkin tidak memberikan hasil yang akurat. Klik ikon pada kolom Missing maka akan muncul dialog box Missing Values. Pada form Discrete, isi angka yang akan dijadikan pengganti missing value, misal: 9, 99, 999, etc. Jika kita memilih angka 9, maka setiap ada data yang tidak diisi (missing value) angka 9 yang harus diisikan, jangan dibiarkan kosong.
- Columns. Kolom ini menunjukkan lebar kolom. baik jenis data numeric maupun string, lebar maksimal 255 digit.
- Align. Kolom ini menunjukkan posisi data pada tiap cell. Terdapat tiga pilihan posisi data, yaitu: left, right, dan center.
- Measure. Kolom ini menunjukkan jenis ukuran data yang digunakan. Terdapat tiga pilihan jenis ukuran data, yaitu: Scale, Nominal, dan Ordinal.